旧漢字の問題は解決していませんでした
Relaxed Typing Mono JP を更新しましたと前回お知らせしたときに、一部が「旧漢字」の字体になっていたのを解決しましたと書きました。しかし、問題が解消されたはずのバージョン 1.03 をインストールしてみると問題は何も変わっていません。そこで、改めて調査して一定の対処をし、バージョン 1.04 をリリースしました。ドタバタですね、うむむ、と振り返りたくなるところです。
直接の原因
1.03 のとき、この問題は CID のマッピングが関係しているのではないかと推測していました。しかし、問題を引き起こしていた直接の原因は compat_map.py にありました。
この変換マップは、CJK 互換漢字のマップです。Noto Sans JP の一部の漢字が本来の文字コードではなく、互換漢字のほうのコードになってしまっていたので、互換漢字のコードを互換元(という表現でいいのかな?)のほうのコードに変換するためにこれを使っていました。つまり、ここで対処したかったケースは、互換漢字のコードに割り振られた字体は存在するが、その互換元のコードに割り振られた字体が存在しないケースです。
ところが、CJK 互換漢字には新漢字と旧漢字の互換情報も含まれていました。今回のケースでは、旧漢字(つまり互換漢字)のコードにも、新漢字(互換元)のコードにも字体が割り振られていたケースで、先に新漢字の字体をペーストしたにもかかわらず、あとから旧漢字の字体も同じコードに上書きしてしまっていたというわけです。
なぜ解決したと思ったのか……
otf2ttf が問題を解消してくれたみたいだ、と思い込んでいたのですが、これは、実際にフォントキャッシュを消しながらレンダリング結果を目視して、問題の解消を確認していたからです。この目視確認に実は勘違いがあったということになります。
問題が発生している原因を論理的に明らかにせず当て推量で済ませてしまったので、こういう勘違いにひっかかってしまったということになるでしょうか。そう追究せずとも結果オーライで問題ないケースもありますし、それには時間的メリットもあるわけですが、しかしそれではやはり確度に問題が出てしまうということにはなりそうです……。このスクリプトは 1.04 で一定の対処はしましたが、また時間ができたらユニコードの調査をしつつ改めて見直してみたいです。
Relaxed Typing Mono JP を更新しました
昨年末に Relaxed Typing Mono JP というフォントを公開したのですが、一部不具合もあったので更新しました。バージョン 1.03 で公開しています。
一部「旧漢字」になっていました
いわゆる「ドッグフードを食べる」ということをやって、実はしばらくして気づいていたのですが、一部の漢字が旧漢字(正字)で表示されてしまっていました。これは CID のマッピングにうまく対応しきれていなかったということなのかなと考えているのですが、これについて詳細を調べる前に、そもそも後述するような問題に突き当たってしまったので、結局原因の調査はしていなかったりします。つまり、別の問題のほうに対処したら解消されていたということです。
具体的には、たとえば「会社」の「社」の字が「社」になってしまうなどの事象が見られていました。このほかにも、「梅」「海」「贈」などなどのそれなりの数の漢字で同様のことが起きていました。元のフォントである Noto Sans JP のまとまった領域の漢字がこれに該当していたようなので、それが原因と関係しているのではないかなと推測しています。
Python 3 にしたらダメだった
python-fontforge というパッケージがなくなって python3-fontforge になっていたので Python 3 に書き直したのですが、Python スクリプトから Noto Sans JP を開こうとすると Segmentation Fault になってしまいました。フォントファイル自体が開けないので、スクリプト側からはどうしようもありません。GUI の FontForge ではフォントを開けていますので、python3-fontforge に何か問題があるということなのかもしれませんし、もっと本体側にちかいほう、FontForge のスクリプティングエンジンに何かあるということなのかもしれません。さらに言えば CID が開けないということなのか Noto Sans JP 固有の何かに引っかかったのかもよくわかりませんが、差し当たってこの問題については、otf2ttf という変換プログラムで Noto Sans JP を TTF に変換してみたところ解消しました。なお、otf2ttf は pip からインストールできるだろうと思います。
TTF に変換してみたところ、上記の旧漢字になってしまう問題は解消されていました。otf2ttf がこの問題にしっかり対応してくれていたということのようです。
さて、今回のこの Segmentation Fault の問題の本質が Python ライブラリ側にあったのかどうかは定かではありませんが、Python 2 から Python 3 への移行に当たっては、それなりに代償があります。今回のように、ことがライブラリに絡んでくると一気に厄介さが増すわけですが、機会があればコミットしたり報告したりできるとよいかなと考えています。もっとも、個人的な事情でここ最近プライベートではプログラミングがなかなかできなくなってきてしまっているのですが……。
Racc で JSON スキーマを生成する DSL を書いてみた
Ruby には Yacc ならぬ Racc というものがあり、Yacc のようなパーサをつくることができます。 Yacc のことやプログラミング言語をつくることに詳しいわけではないのですが、ちょっとお試しをしてみました。 まがりなりにも独自の言語(といっても JSON schema をつくるためだけのもの)ができたことになります。
動機
JSON には、余分なカンマを打てないこと、コメントアウトができないことなど、独特の不便な点があります。また、フィールド(項目)名を " で囲まなければいけないことも、なんとなく私には億劫だったりもします。
もちろん、これらのことは、JSON を YAML で書いて変換するようにしてしまえば問題はないとも言えます。すべての JSON は YAML ですので、これは可能なことです。単に YAML を読み込んで、JSON で出力すればいいだけです。
わざわざ新しい言語を覚えなくてもいいのが JSON や YAML の利点ですから、これで解決できるなら、そうしたほうがいいと言えそうです。
しかし、JSON や YAML の形式で表現しなければいけないことからくる面倒くささがもしあるなら、そこには別言語を試してみる余地もあるのかもしれません。
文法
といった名目で(?)、JSON schema の内容を簡潔に表現する新しい DSL をつくってみました。その文法を簡単にご紹介します。
データ型の表現
データ型は <> で囲んで表現します。
<object> { }
こう書くと
{ "type": "object" }
と同等になります。
プロパティの表現
プロパティは、先頭に + もしくは - をつけて表現します。
+ は required を表します。
ですので、
<object> {
+ name <string>
+ price <number>
}
と書くと、
{ "type": "object", "properties": { "name": { "type": "string" }, "price": { "type": "number" } }, "required": [ "name", "price" ] }
と同等になります。
ボキャブラリの表現
フィールド以外の JSON schema ボキャブラリは @ をつけて表します。
なお、何が定義されたボキャブラリであるかなどは、パーサはまったく関知しません。
<object> {
+ email <string> { @format: "email" }
@additional-properties: false
}
たとえばこのように書くと
{ "type": "object", "properties": { "email": { "type": "string", "format": "email" } }, "required": [ "email" ], "additionalProperties": false }
こうなります。
キーワードの表現
$id や $schema などのキーワードは、基本的に $ をつけてそのまま書きます。
<object> {
$schema: "http://..."
}
と書けば
{ "type": "object", "$schema": "http://..." }
ということになります。
ただし、$id は {} の外にも書けるようになっています。これは、id を名前のように目立たせたい場合があると思ったからです。
$id: "http://example.com/foo.schema.json"
<object> { }
これは
{ "$id": "http://example.com/foo.schema.json", "type": "object" }
となります。
$defs と $ref の表現
$defs と $ref は、若干わかりにくいかと思いました。ですので、こんなふうに書けるようにしてみました(もう少しこなれたものにしたいところです)。
<array> {
@items: [
{ $ref: (ref employee) }
]
def employee is <object> {
+ name <string>
+ email <string> { @format: "email" }
- date-of-birth <string> { @format: "date" }
}
}
こう書くと、
{ "type": "array", "items": [ { "$ref": "#/$defs/employee" } ], "$defs": { "employee": { "type": "object", "properties": { "name": { "type": "string" }, "email": { "type": "string", "format": "email" }, "dateOfBirth": { "type": "string", "format": "date" } }, "required": [ "name", "email" ] } } }
こうなります。
リポジトリ
プログラムはこちらのリポジトリから見ていただけます。 ただ、お試しの迷い書き状態なので、実装できていないことやバグも多いかなと思います(テスト書きます)。
「サブセット」WOFF をつくってみる(1)
フォント関係の記事を Qiita で見ていましたら、ウェブでの表示用に「サブセット化」するというニーズもあるそうです。
日本語Webフォントの流行の最適化「NotoSans」「サブセット化」 | Qiita
こうしたサブセットは、FontForge のスクリプトでもつくることはできそうです。 差し当たって、ここではまず常用漢字のリストを取得することを考えてみましょう。
Wikipedia から常用漢字を取得してみる
常用漢字一覧の入手元としては候補はいくつかありそうですが、ここでは こちらの Wikipedia のページから取得してみることにします。 ページのレスポンスを次のように取得できるので
import urllib.parse from urllib.request import Request, urlopen uri = urllib.parse.quote(u"//ja.wikipedia.org/wiki/常用漢字一覧") response = urlopen(Request(f"https:{uri}"))
ここで得た response をつかって、XPath で希望の箇所をだけ抜き取ってみます。
from lxml import etree tree = etree.parse(response, etree.HTMLParser()) hans = tree.xpath(u"//h2//span[text()='一覧']/following::table[1]//tr[not(@style)]/child::td[2]/a/text()") for c in hans: print(c)
もちろん、スクレイピングは記事の書かれ方に依存してしまいますから、永続的にこれで期待の結果が得られる保証はありません。たとえば、ここでは「削除された漢字の列には style が当たっている」とみなしていますし、目的の漢字は td の直下の a に書かれているとみなしています。
ところで、これを実際に動かして wc -l で行数をみると、2137 返ってきてしまいます。Wikipedia の表は、行にインデックスが振られているので漢字の総数がわかりますが、漢字の数は 2136 のはずですから、1 つ多いです。
なぜだろうと思って、ためしに sort してみたりすると、ひとつ毛色のちがうものが見つかります。表をよくみると 830 個目に漢字が 2 つあるのですね。Wikipedia の著者、かなり知識が細かいです (^^;
次回もしできそうだったら、このリストをつかって WOFF をつくってみましょう(そんな記事は書かないかもしれませんが)。
CJK互換漢字について
昨日 Relaxed Typing Mono JP というフォントについて記事を書きました。
Github のプロジェクトページでフォント生成スクリプトを確認すると、compat_map.py というやたらと長い dictionary があります。これが何なのか、もしピンとくる方がいらっしゃるなら、かなり Unicode に詳しい方ではないでしょうか。
CJK 互換漢字のリストが必要なわけ
この長大な dictionary は「CJK 互換漢字(CJK Compatibility Ideographs)」のリストです。文字コードには、いろいろ思わぬ点があり、同じ字形に対して複数の文字コードが割り振られている場合があります。この互換漢字はそのひとつです。
Relaxed Typing Mono JP の合成元である Noto Sans JP は CID フォントですが、各グリフには Unicode 値も振られています。しかし、この値が互換漢字のほうの値で振られている場合もあるようです。CID フォントについて詳しいわけではないので、これが Noto Sans JP に固有のことなのかはわかりませんが、今回のケースでは、この変換マップが必要になりました(実質的には、ここまで長い dictionary である必要はなかったかもしれませんが、機械的につくったものですので)。
同じ字形に異なるコード値が割り振られているとは
CJK 互換漢字について、ざっとした説明を書きましたが、ざっとしすぎたきらいがあるので、具体例も紹介しておきたいと思います。
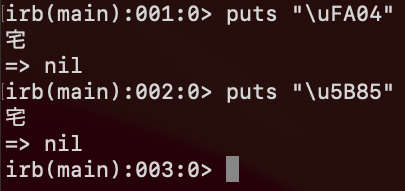
同じ字形に異なるコード値が振られているとはどういうことか、たとえば U+FA04 は、CJK 互換漢字のブロックに含まれる文字ですが、これは U+5B85 と互換関係にあるということです。つまり、
$ python >>> print(u"\uFA04") 宅 >>> print(u"\u5B85") 宅
ということです。つまり、「宅」という字形を示すコード値は、ふつうは U+5B85 ですが、この字は互換漢字の対象なので U+FA04 のこともないわけではないということです。
Source Code Pro と Noto Sans JP を組み合わせてフォントをつくりました
Source Code Pro と Noto Sans JP を組み合わせて、等幅フォントをつくりました。Relaxed Typing Mono JP という名前で公開しています。ライセンス上、似た名前にするのが憚られましたので、関係ない新しい名前を考えました。
Source Code Pro と Noto Sans JP を組み合わせたフォントには、すでに Source Han Code JP があります。ただ、Source Han Code JP は、英数字と漢字(ひらがな等含む)の文字幅の比が 3:5 なのです。英字 2 文字が漢字 1 文字より幅が広くなってしまうので、期待したようには桁が揃わないのが難点でした。
そこで、英数字と漢字の文字幅が 1:2 になるように調整したものをつくったというわけです。
■ 表示例

■ ダウンロード
ダウンロードはこちらからおこなえます。お試しください。